
Note: you can download the jupyter notebook for this post here and the CSV files I used: 1 2 3 4
It’s time for some neeeeerd pledge. I was talking to Adam and Geoff and though they run a segment called nerd pledge, I discovered they really need to up their cricket nerd stats game. So I’m here to help.
The problem is, writing custom queries is difficult if it’s not something obvious on statsguru. So I’m going to answer a couple of questions:
- what is the most number of innings in a row a player has made greater than 40?
- which team has scored the most innings in a row less than 200?
This type of consecutive stat is actually quite a hard thing to do, sounds like a database task. This will be a ramble of my journey to answer these questions, but my goal is to have a “generic query” and then produce answer to that generic query. Okay, let’s find some data!
I downloaded the files we need from this dataset. I just run these bash commands to rename the files for easier shell handling
# replace space with underscores, spaces are yukky
find *.csv -exec rename 's/\s/_/g' {} \;
# make all files lowercase
find *.csv -exec rename 'y/A-Z/a-z/' {} \;
#To fix up the headings, we do the same for the first line in all the csv files.
#
#1s/.*/\L&/ < on the first line, make sure all characters are lowercase \L
#1s/ /_/g ... on the first line, replace all spaces with underscores, globally
find *.csv -exec sed -i '1s/.*/\L&/;1s/ /_&/' {} \;
I did attempt to start this with SQL, but I found it such a pain that I decided to best tool is the one you’ve vaguely used before, so we’re going with pandas. I will spare you my SQL adventure, it got a bit messy. 🍻🤢
Okay that’s it. We’ve done the file processing, now to load them all into jupyter.
I’m just going to be looking at the Men’s test individual data. But you could do the same for the women, ODIs, etc. Just load those into the dataframe instead.
import pandas as pd
import numpy as np
import glob
all_files = glob.glob('data/men_test_player_innings_stats_-_*.csv')
# low_memory=False just tries to figure out the data type of large files.
# we don't really need this, because we'll fix these later.
df = pd.concat((pd.read_csv(f, low_memory=False) for f in all_files))
There’s a few things we should do before we can start processing the data.
- drop the duplicate rows
- change the type of data to the appropriate data type in each column (I definitely knew about this before starting the post, yep, definitely)
- sort by date, then innings number - to ensure all the innings are in order.
df = df.drop_duplicates()
int_cols = ['innings_runs_scored_num', 'innings_minutes_batted',
'innings_batted_flag', 'innings_not_out_flag', 'innings_bowled_flag',
'innings_balls_faced', 'innings_boundary_fours',
'innings_boundary_sixes', 'innings_maidens_bowled',
'innings_runs_conceded', 'innings_wickets_taken',
'4_wickets', '5_wickets', '10_wickets'
]
for col in int_cols:
# use to_numeric to convery the - to NaN (not-a-number)
# "Int32" has mixed NaNs and integers
df[col] = pd.to_numeric(df[col], errors='coerce').astype("Int32")
df.innings_economy_rate = pd.to_numeric(df.innings_economy_rate, errors='coerce')
df.innings_date = pd.to_datetime(df.innings_date, infer_datetime_format=True)
df = df.sort_values(by=['innings_date', 'innings_number'])
Okay, so now we’ve gotten to the point where we hoped we would have started, clean data, I guess. How do we know we haven’t fucked something up?
Well, Don Bradman’s test batting average was 99.94, how about we write a function to check the average is correct.
The average of a batter is the number of runs scored in their career minus the number of times they have been dismissed.
So we can write a function for each.
def get_total_runs(player):
return df.loc[df['innings_player'] == player, 'innings_runs_scored_num'].sum()
def times_dismissed(player):
num_innings = len(df.loc[df['innings_player'] == player, 'innings_runs_scored_num'].dropna())
not_out = df.loc[df['innings_player'] == player, 'innings_not_out_flag'].sum()
return num_innings - not_out
def get_average(player):
runs = get_total_runs(player)
dismissed = times_dismissed(player)
if dismissed == 0:
return np.nan
return runs / dismissed
print(get_average('DG Bradman'))
99.94285714285714
Fuckn yeh boooooiiiii! 😎
That was fun an all, but really, what we want is to do some fucking number crunching here. We can calculate the average of every player in the history of the game.
That will tell us who the real greatest player of all time is.
First we want to get all the players…
all_players = df.innings_player.drop_duplicates()
That will just give us a pandas Series, but I want to make it into a DataFrame and add the column for the average for each player
all_players = pd.DataFrame(all_players)
You can use the apply function to apply the function to all values, who’d have thought that’s what it would do?
all_players['average'] = all_players.innings_player.apply(get_average)
After that we should filter out the infinite and not-a-number results
# filter out infinite and not-a-number results
all_players.replace([np.inf, -np.inf], np.nan, inplace=True)
all_players.dropna(inplace=True)
Next we can displayer the results from highest to lowest. To reveal the best batsman of all time….
all_players.sort_values(by=['average'], ascending=False, inplace=True)
print(all_players.head(10))
innings_player average
22755 KR Patterson 144.000000
66931 AG Ganteaume 112.000000
48719 Abid Ali 107.000000
50574 DG Bradman 99.942857
62077 MN Nawaz 99.000000
60884 VH Stollmeyer 96.000000
85275 DM Lewis 86.333333
69175 Abul Hasan 82.500000
91237 RE Redmond 81.500000
30714 DJ Mitchell 73.000000
Holy fuck. This can’t be fucking real.
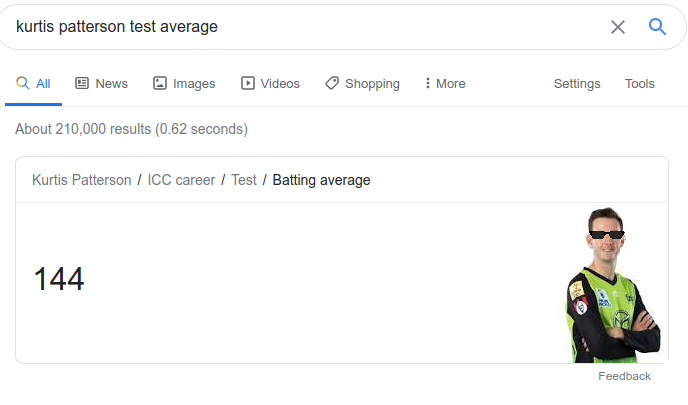
It fucking is!
Whoa, mind is actually blown. Okay, that was fun and all. But it was really fucking slow. Like, real slow: Wall time: 1min 17s I think I’ve been going about this the wrong way. We’ll fix it later, maybe.
Okay, let’s just make sure our data is all good, what does it take to caluculate the number of ducks a player got in their career? So the number of ducks is the number they scored 0 and were also dismissed, so we can do a simple calculate to figure out how many times Don Bradman got a duck:
def get_all_player_stats(player):
# return the entire dataframe but filtered for that player
return df.loc[df['innings_player'] == player]
def num_ducks(player):
all_stats = get_all_player_stats(player)
ducks = all_stats[(all_stats.innings_not_out_flag == 0) & (all_stats.innings_runs_scored_num == 0)]
return len(ducks)
print(f"The Don got {num_ducks('DG Bradman')} ducks")
The Don got 7 ducks
Okay, so we’ve done that for the simple stuff. Now we’re going to start answering the real questions, that stats that statsguru doens’t want you to know. Won’t let you know. Actively withholding important cricketing knowledge from you! Let’s get started!
When I first did this, it took 2min 14s to perform one query. That’s not okay. With the method below I get 18.2 s for the same query. Not actually as fast as I was hoping, but much better than going away to boil the kettle, come back and it’s still not bloody done. Good-e-fucking-nuf mate. I’m just showing you the shiny new approach, you don’t want to see the old way. Trust me.
The problem with calculating the averages above was that I was sorting the original dataset by date, and not by player, then getting the individual players in a separatate dataframe. Then, for each player we were going over the whole dataframe to get the average. That way, we already have the players grouped together, and we don’t need to pass over the whole dataframe each time for every player, we can just group by player which is already sorted, and then apply our function for each group. Let’s give that a red hot go ay. Fucken-ay.
def get_max_consecutive(group):
# thanks stackoverflow https://stackoverflow.com/a/59640568/5905582
# this works for each player
# first get all matches and compare with a shifted version to how many are the same in a row
df_bool = group['criteria_match'] != group['criteria_match'].shift()
# take the cumulative sum of the matches in a row to get the number of each
df_cumsum = df_bool.cumsum()
# then groupby the size of each group
search_groups = group.groupby(df_cumsum)
# the above will give us the size, but we also want the raw data out of each
# so below we are getting the indexes from the original dataset so we can look them up later
# what we want is the longest group where criteria_match == True
# make a dictionary with the key the name, but store each length
lengths = {n: len(g) for n,g in search_groups if g['criteria_match'].all() == True}
try:
# m is the maximum number of matches
m = max(lengths.values())
except ValueError:
# if there are no matches, return 0 and not-a-number
return pd.DataFrame({'maximum': [0], 'num_results':0, 'indexes':[np.nan]})
# get a list of groups where the match is the players maximum value
# includes if a player matches multiple times
all_groups = [search_groups.get_group(key) for key,val in lengths.items()]
max_groups_list = [search_groups.get_group(key) for key,val in lengths.items() if val == m]
num_items = len(max_groups_list)
return pd.DataFrame({'maximum': [m]*num_items,
'num_results': [num_items]*num_items,
'indexes': [g['index'].values for g in max_groups_list],
})
def get_all_consecutive(criteria, data, sort_order=['innings_player', 'innings_date', 'innings_number']):
data = data.sort_values(by=sort_order)
data.reset_index(inplace=True)
# drop all columns where the values were after doesn't exist
all_columns = list(data.columns.values)
for c in all_columns:
if c in criteria:
data = data[data[c] != np.nan]
# find all matches and set them to true, set non-matches to False
data.loc[data.eval(criteria), 'criteria_match'] = True
data['criteria_match'].fillna(False, inplace=True)
# group by all the search item, and then actually do the check for each one.
search_item = all_columns[1]
grp = data.groupby(search_item)
results = grp.apply(get_max_consecutive)
return results
Read the code comments for explanations of what each part is doing. I tried to make it clear. I’ll tell you now, that section took me a four or five days on and off. For like 20 lines of code, and most of those I’d written already. What a brainfuck.
The line that runs the actual query is this function data.eval(criteria), and we mark each item in our dataframe as a match or not:
data.loc[data.eval(criteria), 'criteria_match'] = True
data['criteria_match'].fillna(False, inplace=True)
Then we groupby the players, and apply the get_max_consecutive function for each player.
Okay, let’s try this bloody thing out!
First we’ll just get the all_consecutive that match a particular criteria. In this case the players who scored the most runs over 40 in a row.
criteria = 'innings_runs_scored_num > 40'
results = get_all_consecutive(criteria, all_players.copy())
results.sort_values(by=['maximum'], ascending=False, inplace=True)
print(results.head(10))
maximum num_results \
innings_player
JH Kallis 0 9 1
ED Weekes 0 9 1
Inzamam-ul-Haq 0 8 1
IVA Richards 0 8 1
KF Barrington 0 8 1
A Flower 0 8 1
GS Sobers 0 7 1
Javed Miandad 0 7 1
KL Rahul 0 7 1
S Chanderpaul 0 7 1
indexes
innings_player
JH Kallis 0 [131980, 132561, 132651, 132935, 133103, 13318...
ED Weekes 0 [23536, 24007, 24072, 24291, 24336, 24469, 245...
Inzamam-ul-Haq 0 [101702, 101823, 101845, 102044, 102175, 10221...
IVA Richards 0 [68896, 69313, 69556, 69601, 70364, 70409, 704...
KF Barrington 0 [42547, 42591, 42613, 42657, 42702, 42790, 428...
A Flower 0 [119766, 119788, 120073, 120116, 120250, 12027...
GS Sobers 0 [35073, 35241, 35394, 35436, 35590, 35745, 35789]
Javed Miandad 0 [75473, 75538, 75605, 75671, 76655, 76700, 76789]
KL Rahul 0 [179630, 179675, 180018, 180181, 180246, 18096...
S Chanderpaul 0 [144318, 145407, 145715, 145759, 145781, 14582...
We want more just that players and how many times that player matched that condition. Like a dog hankering for a fresh bone, I can feel you chomping at the bit to get the real stats. We want to get the actual innings that the player where they match the query. That’s what that indexes column is for. It’s a list of the indivdidual indexes from the original dataset so we can look them up later. Let’s write a function that does the whole thing, and returns the innings for only the maximum results.
def get_most_consecutive_individual(criteria, data=all_players.copy(), sort_order=['innings_player', 'innings_date', 'innings_number']):
results = get_all_consecutive(criteria, data, sort_order)
# get the maximum result
max_value = results['maximum'].max()
# get all matches to the maximum
max_results = results[results['maximum'] == max_value]
# get the matches out of the original dataset to get the innings
result_data = data.reindex(np.concatenate(max_results.indexes.values))
return max_value, result_data
Then we can call the function and print only the columns we’re interested in.
criteria = 'innings_runs_scored_num > 40'
max_value, results = get_most_consecutive_individual(criteria)
print(max_value)
cols_to_print = ['innings_player', 'innings_runs_scored', 'opposition' ,'ground', 'innings_date',
'innings_minutes_batted', 'innings_number']
print(results[cols_to_print])
9
innings_player innings_runs_scored opposition ground \
23536 ED Weekes 141 v England Kingston
24007 ED Weekes 128 v India Delhi
24072 ED Weekes 194 v India Mumbai (BS)
24291 ED Weekes 162 v India Kolkata
24336 ED Weekes 101 v India Kolkata
24469 ED Weekes 90 v India Chennai
24534 ED Weekes 56 v India Mumbai (BS)
24578 ED Weekes 48 v India Mumbai (BS)
25490 ED Weekes 52 v England Manchester
131980 JH Kallis 43 v Pakistan Faisalabad
132561 JH Kallis 158 v West Indies Johannesburg
132651 JH Kallis 44 v West Indies Johannesburg
132935 JH Kallis 177 v West Indies Durban
133103 JH Kallis 73 v West Indies Cape Town
133188 JH Kallis 130* v West Indies Cape Town
133277 JH Kallis 130* v West Indies Centurion
133584 JH Kallis 92 v New Zealand Hamilton
133627 JH Kallis 150* v New Zealand Hamilton
innings_date innings_minutes_batted innings_number
23536 1948-03-27 <NA> 2
24007 1948-11-10 194 1
24072 1948-12-09 <NA> 1
24291 1948-12-31 188 1
24336 1948-12-31 <NA> 3
24469 1949-01-27 <NA> 1
24534 1949-02-04 <NA> 1
24578 1949-02-04 <NA> 3
25490 1950-06-08 103 2
131980 2003-10-24 174 3
132561 2003-12-12 411 1
132651 2003-12-12 96 3
132935 2003-12-26 479 2
133103 2004-01-02 207 1
133188 2004-01-02 262 3
133277 2004-01-16 247 1
133584 2004-03-10 239 1
133627 2004-03-10 406 3
The good thing about this system is, we can add as many conditions as we like. So what’s the most number of matches where a player has scored over 60 and was also not_out. We can search by using the column heading and a condition as many conditions as we like (joined by and)
criteria = 'innings_runs_scored_num > 60 and innings_not_out_flag == 1'
max_value, results = get_most_consecutive_individual(criteria)
print(max_value)
cols_to_print = ['innings_player', 'innings_runs_scored', 'opposition' ,'ground', 'innings_date',
'innings_minutes_batted', 'innings_number']
print(results[cols_to_print])
3
innings_player innings_runs_scored opposition ground \
126481 JH Kallis 61* v Australia Durban
128241 JH Kallis 75* v Bangladesh East London
128394 JH Kallis 139* v Bangladesh Potchefstroom
176275 LRPL Taylor 173* v Zimbabwe Bulawayo
176562 LRPL Taylor 124* v Zimbabwe Bulawayo
176606 LRPL Taylor 67* v Zimbabwe Bulawayo
126787 S Chanderpaul 67* v India Port of Spain
126898 S Chanderpaul 101* v India Bridgetown
126985 S Chanderpaul 136* v India St John's
134993 S Chanderpaul 101* v Bangladesh Kingston
135332 S Chanderpaul 128* v England Lord's
135376 S Chanderpaul 97* v England Lord's
149100 S Chanderpaul 107* v Australia North Sound
149145 S Chanderpaul 77* v Australia North Sound
149254 S Chanderpaul 79* v Australia Bridgetown
170381 S Chanderpaul 85* v Bangladesh Kingstown
170468 S Chanderpaul 84* v Bangladesh Gros Islet
170512 S Chanderpaul 101* v Bangladesh Gros Islet
innings_date innings_minutes_batted innings_number
126481 2002-03-15 159 4
128241 2002-10-18 185 1
128394 2002-10-25 266 2
176275 2016-07-28 365 2
176562 2016-08-06 240 1
176606 2016-08-06 125 3
126787 2002-04-19 260 4
126898 2002-05-02 365 2
126985 2002-05-10 675 2
134993 2004-06-04 271 2
135332 2004-07-22 383 2
135376 2004-07-22 231 4
149100 2008-05-30 352 2
149145 2008-05-30 336 4
149254 2008-06-12 226 2
170381 2014-09-05 302 1
170468 2014-09-13 268 1
170512 2014-09-13 173 3
So the most in test history is 3. But Chanderpaul has done that four fucking times. Also, I can’t tell you how satisfying it is when my queries run in a few seconds. Lets try another query, what’s most number of times in a row someone has batted more than 200 minutes, but not scored a century?
criteria = 'innings_runs_scored_num < 100 and innings_minutes_batted > 200'
max_value, results = get_most_consecutive_individual(criteria)
print(max_value)
print(results[cols_to_print])
4
innings_player innings_runs_scored opposition ground \
73183 DI Gower 74 v India Kolkata
73338 DI Gower 64 v India Chennai
73382 DI Gower 85 v India Kanpur
73535 DI Gower 89 v Sri Lanka Colombo (PSS)
180059 JA Raval 80 v South Africa Wellington
180170 JA Raval 88 v South Africa Hamilton
182351 JA Raval 42 v West Indies Wellington
182567 JA Raval 84 v West Indies Hamilton
103824 RG Twose 36 v India Cuttack
104275 RG Twose 59 v Pakistan Christchurch
104351 RG Twose 51* v Pakistan Christchurch
104682 RG Twose 42 v Zimbabwe Hamilton
149145 S Chanderpaul 77* v Australia North Sound
149254 S Chanderpaul 79* v Australia Bridgetown
149300 S Chanderpaul 50 v Australia Bridgetown
150729 S Chanderpaul 76 v New Zealand Dunedin
innings_date innings_minutes_batted innings_number
73183 1982-01-01 235 3
73338 1982-01-13 215 2
73382 1982-01-30 257 1
73535 1982-02-17 256 2
180059 2017-03-16 253 3
180170 2017-03-25 396 2
182351 2017-12-01 220 2
182567 2017-12-09 231 1
103824 1995-11-08 204 2
104275 1995-12-08 210 2
104351 1995-12-08 257 4
104682 1996-01-13 227 1
149145 2008-05-30 336 4
149254 2008-06-12 226 2
149300 2008-06-12 201 4
150729 2008-12-11 281 2
Our mate Chanderpaul again. Never thought of him as a slow-poke like a Gower. But there you go. You may be wondering what the sort_order is for. Well, individual/time is the most likely order. So the default is to use
['innings_player', 'innings_date', 'innings_number'] as the search order.
What if we wanted to instead, find out who did something at a particular ground, or against a particular opposition. Let’s see the most innings in Kolkata where bowlers have taken at least 3 wickets.
# double quotes around the text (string) is important
criteria = 'innings_wickets_taken >= 3 and ground == "Kolkata"'
# sorting by player, ground, data, number groups the players together
sort_order = ['innings_player', 'ground', 'innings_date', 'innings_number']
# the reason for get_all instead of get_most is sometimes we want to know all the top players that satisfy the condition
# we the get_most function gets the innings from the 'indexes' column
# look at the code inside the get_most function to see how it looks up the indexes from the original dataset
results = get_all_consecutive(criteria, df.copy(), sort_order)
results.sort_values(by=['maximum'], ascending=False, inplace=True)
print(results.head(10)['maximum'])
innings_player
Mohammed Shami 0 5
J Srinath 0 4
A Kumble 0 4
R Benaud 0 4
BS Chandrasekhar 0 3
AME Roberts 0 3
Ghulam Ahmed 0 3
Harbhajan Singh 0 3
WW Hall 0 2
SA Durani 0 2
Name: maximum, dtype: int64
What about in a country? Let’s see which bowlers have taken 3 or more wickets in a row in England. To get a whole country, all we really have to go on is the grounds, so we can build up a query to check or each of those grounds. Like below:
# we need to get all the english grounds out of our dataset. I might have missed some. I was lazy with this.
english_grounds = ["Lord's", "Birmingham", "Manchester", "The Oval", "Sheffield", "Nottingham", "Leeds"]
# this is how you can build it up programmatically, start with the beginning of the query
criteria = 'innings_wickets_taken >= 3 and (ground == '
# this next line is tricky, have to wrap each item in double quotes ""
criteria += ' or ground == '.join(f'"{g}"' for g in english_grounds)
# finish it off by closing the brackets
criteria += ')'
# print so you see that the final criteria looks like
print(criteria)
# sorting by player, ground, data, number groups the players together
sort_order = ['innings_player', 'ground', 'innings_date', 'innings_number']
results = get_all_consecutive(criteria, df.copy(), sort_order)
# print(results.dropna())
results.sort_values(by=['maximum'], ascending=False, inplace=True)
# select 'maximum' so you don't have to see the indexes
print(results.head(10)['maximum'])
innings_wickets_taken >= 3 and (ground == "Lord's" or ground == "Birmingham" or ground == "Manchester" or ground == "The Oval" or ground == "Sheffield" or ground == "Nottingham" or ground == "Leeds")
innings_player
GD McGrath 0 6
RR Lindwall 0 6
T Richardson 0 6
GP Swann 0 6
SK Warne 0 6
D Gough 0 6
IT Botham 0 5
AV Bedser 0 5
SF Barnes 0 5
CA Walsh 0 5
Name: maximum, dtype: int64
Ooh ahh, Glenn McGrath.
Okay, now we want to apply our data to team scores not just individuals. Well, the data we downloaded did not have all the indvidual team innings, unfortunately. But the data does exist on statsguru. So, I’ve modified a scraper that I found online to download the data. You can check out my repo here
Here’s the relevent part:
# replace the URL to the search query we want.
self.baseurl = "http://stats.espncricinfo.com/ci/engine/stats/index.html?class=1;orderby=start;page=%s;template=results;type=team;view=innings"
The score is not a nice integer of runs - we can do maths on things with a /, so I added a runs column.
# the runs are the number before the /, if it exists
runs = score.split('/')[0]
if runs == 'DNB':
runs = 0
values.insert(2, runs)
Some of the balls per over was not 6, but is says when it wasn’t. So I added a balls_per_over so it’s possible to calculate the number of deliveries in each innings if needed.
# value looks like 50x8 < 50 8 ball overs
# split by the x, and part before is the number over overs
# the part after is the balls per over.
overs_and_balls = values[2].split('x')
values[2] = overs_and_balls[0]
balls_per_over = 6
if len(overs_and_balls) == 2:
balls_per_over = overs_and_balls[1]
values.insert(3, balls_per_over)
Okay… I the scraper from the internet and required only 1 line change to actually work. Amazing.
$ python scraper.py
print('All done')
Noice.
But we’re going to make a _team function, we’ll it’ll be just like the _individual one we did earlier, but have a default sort_order that is sensible for teams. That’s the only difference. But first we’ve gotta read the data into pandas.
all_innings_file = 'data/all_test_innings.csv'
all_innings = pd.read_csv(all_innings_file)
all_innings.start_date = pd.to_datetime(all_innings.start_date, infer_datetime_format=True)
all_innings.runs = pd.to_numeric(all_innings.runs, errors='coerce').astype("Int64")
In fact, to do the team one, we just call the individual one but pass in the default values we want.
def get_most_consecutive_team(criteria, data=all_innings.copy(), sort_order=['team', 'start_date', 'innings']):
return get_most_consecutive_individual(criteria, data, sort_order)
…that was easy.
Okay, let’s run the fucker and find out who scored the most innings in a row under 200.
criteria = 'runs < 200'
max_value, results = get_most_consecutive_team(criteria)
print(max_value)
print(results)
21
team score runs overs balls_per_over rpo lead innings result \
80 Australia 123 123 118.3 4 1.55 105 3 lost
83 Australia 121 121 82.3 4 2.19 -232 2 lost
84 Australia 126 126 111.1 4 1.69 -106 3 lost
86 Australia 68 68 60.2 4 1.68 -366 2 lost
87 Australia 149 149 97.0 4 2.30 -217 3 lost
89 Australia 119 119 113.1 4 1.57 74 2 lost
91 Australia 97 97 107.0 4 1.35 -13 4 lost
93 Australia 84 84 55.1 4 2.28 -67 2 lost
95 Australia 150 150 110.0 4 2.04 -71 4 lost
97 Australia 42 42 37.3 4 1.66 -71 2 lost
99 Australia 82 82 69.2 4 1.76 -126 4 lost
100 Australia 116 116 71.2 4 2.43 116 1 won
102 Australia 60 60 29.2 4 3.05 123 3 won
104 Australia 80 80 90.3 4 1.32 80 1 lost
106 Australia 100 100 69.2 4 2.15 -137 3 lost
108 Australia 81 81 52.2 4 2.31 -91 2 lost
109 Australia 70 70 31.1 4 3.36 -21 3 lost
117 Australia 132 132 86.0 5 1.84 132 1 lost
119 Australia 176 176 140.2 5 1.50 135 3 lost
121 Australia 92 92 65.2 5 1.68 92 1 lost
123 Australia 102 102 60.2 5 2.02 94 3 lost
opposition ground start_date all_out_flag declared_flag
80 v England Manchester 1886-07-05 1 0
83 v England Lord's 1886-07-19 1 0
84 v England Lord's 1886-07-19 1 0
86 v England The Oval 1886-08-12 1 0
87 v England The Oval 1886-08-12 1 0
89 v England Sydney 1887-01-28 1 0
91 v England Sydney 1887-01-28 1 0
93 v England Sydney 1887-02-25 1 0
95 v England Sydney 1887-02-25 1 0
97 v England Sydney 1888-02-10 1 0
99 v England Sydney 1888-02-10 1 0
100 v England Lord's 1888-07-16 1 0
102 v England Lord's 1888-07-16 1 0
104 v England The Oval 1888-08-13 1 0
106 v England The Oval 1888-08-13 1 0
108 v England Manchester 1888-08-30 1 0
109 v England Manchester 1888-08-30 1 0
117 v England Lord's 1890-07-21 1 0
119 v England Lord's 1890-07-21 1 0
121 v England The Oval 1890-08-11 1 0
123 v England The Oval 1890-08-11 1 0
Holy fucking shit. For a team with the highest win record, we have by far the worst losing streak. God damn.
For whatever reason, maybe recency-bias, you might want to restrict your entire search-space to a particular date range. Maybe we want to find the answer to this question between 1950 and 1990 or something. This can be done by pre-filtering the data before we make the query.
# year, month, day
start_date = datetime.datetime(1950, 1, 1)
end_date = datetime.datetime(1990, 1, 1)
# filter by date,use & (and), and brackets for multiple pre-filtering conditions
filtered_data = all_innings[(all_innings.start_date >= start_date) & (all_innings.start_date <= end_date)]
# if you just wanted it to be since 1950
# filtered_data = all_innings[all_innings.start_date >= start_date]
criteria = 'runs < 200'
max_value ,results = get_most_consecutive_team(criteria, data=filtered_data)
print(max_value)
print(results)
7
team score runs overs balls_per_over rpo lead innings \
1530 New Zealand 157/9d 157 80.0 6 1.96 267 3
1638 New Zealand 94 94 69.3 6 1.35 -127 2
1640 New Zealand 137 137 77.3 6 1.76 -205 4
1642 New Zealand 47 47 32.3 6 1.44 -222 2
1643 New Zealand 74 74 50.3 6 1.46 -148 3
1644 New Zealand 67 67 59.1 6 1.13 67 1
1646 New Zealand 129 129 101.2 6 1.27 -71 3
result opposition ground start_date all_out_flag declared_flag
1530 won v West Indies Auckland 1956-03-09 0 1
1638 lost v England Birmingham 1958-06-05 1 0
1640 lost v England Birmingham 1958-06-05 1 0
1642 lost v England Lord's 1958-06-19 1 0
1643 lost v England Lord's 1958-06-19 1 0
1644 lost v England Leeds 1958-07-03 1 0
1646 lost v England Leeds 1958-07-03 1 0
I think we need to drill deeper into this though. Let’s get all the occurances.
criteria = 'runs < 200'
sort_order=['team', 'start_date', 'innings']
results = get_all_consecutive(criteria, data=all_innings.copy(), sort_order=sort_order)
results.sort_values(by=['maximum'], ascending=False, inplace=True)
print(results['maximum'])
team
Australia 0 21
Bangladesh 0 12
South Africa 0 12
England 0 8
New Zealand 0 7
West Indies 0 6
Pakistan 0 5
India 0 5
1 5
Zimbabwe 0 4
Sri Lanka 1 4
0 4
Afghanistan 0 2
1 2
ICC World XI 0 2
Ireland 2 1
0 1
1 1
Name: maximum, dtype: int64
… I still have no idea what that first column even is. Some indexy-thingo-maybe. Oh well, who cares, certainly not me 🤷♂️
One shortcoming of this current implementation is underneath it all I’m calling get_max_consecutive for each group. So we only ever discover the maximum number of matches, not all the available matches, as well as the maximum. I can probably be convinced to add this. But I’ve worked on this for longer than is reasonable already.
Okay, extra conditions also works with teams.
criteria = 'runs < 150 and all_out_flag == 1'
max_value, results = get_most_consecutive_team(criteria)
print(max_value)
print(results)
9
team score runs overs balls_per_over rpo lead innings result \
97 Australia 42 42 37.3 4 1.66 -71 2 lost
99 Australia 82 82 69.2 4 1.76 -126 4 lost
100 Australia 116 116 71.2 4 2.43 116 1 won
102 Australia 60 60 29.2 4 3.05 123 3 won
104 Australia 80 80 90.3 4 1.32 80 1 lost
106 Australia 100 100 69.2 4 2.15 -137 3 lost
108 Australia 81 81 52.2 4 2.31 -91 2 lost
109 Australia 70 70 31.1 4 3.36 -21 3 lost
117 Australia 132 132 86.0 5 1.84 132 1 lost
opposition ground start_date all_out_flag declared_flag
97 v England Sydney 1888-02-10 1 0
99 v England Sydney 1888-02-10 1 0
100 v England Lord's 1888-07-16 1 0
102 v England Lord's 1888-07-16 1 0
104 v England The Oval 1888-08-13 1 0
106 v England The Oval 1888-08-13 1 0
108 v England Manchester 1888-08-30 1 0
109 v England Manchester 1888-08-30 1 0
117 v England Lord's 1890-07-21 1 0
LOL. Australia really sucked in 1888.
Okay, just out of curiosity, which team was not out most in a row.
criteria = 'all_out_flag == 0'
max_value, results = get_most_consecutive_team(criteria)
print(max_value)
print(results)
9
team score runs overs balls_per_over rpo lead innings \
5550 New Zealand 196/1d 196 73.0 6 2.68 101 3
5564 New Zealand 407/4d 407 112.2 6 3.62 303 2
5654 New Zealand 287/8d 287 88.4 6 3.23 -199 2
5656 New Zealand 274/6 274 57.0 6 4.80 -9 4
5677 New Zealand 243/7 243 105.2 6 2.30 -315 2
5682 New Zealand 534/9d 534 162.5 6 3.27 534 1
5684 New Zealand 256/9d 256 71.0 6 3.60 439 3
5698 New Zealand 365/9d 365 77.1 6 4.73 365 1
5705 New Zealand 341/6d 341 88.0 6 3.87 209 2
result opposition ground start_date all_out_flag \
5550 draw v Pakistan Christchurch 2001-03-15 0
5564 won v Pakistan Hamilton 2001-03-27 0
5654 draw v Australia Brisbane 2001-11-08 0
5656 draw v Australia Brisbane 2001-11-08 0
5677 draw v Australia Hobart 2001-11-22 0
5682 draw v Australia Perth 2001-11-30 0
5684 draw v Australia Perth 2001-11-30 0
5698 won v Bangladesh Hamilton 2001-12-18 0
5705 won v Bangladesh Wellington 2001-12-26 0
declared_flag
5550 1
5564 1
5654 1
5656 0
5677 0
5682 1
5684 1
5698 1
5705 1
And everyone’s second favourite team, New Zealand, coming home with the goods. I’m going to leave it there. If you see something wrong with my data or if you have any features you’d like to see. Please let me know.
You can download the jupyter notebook of a modified version of this blog post, link at the top. I’ve edited it a little but if you just wanna run the code, you can pretty easily. Just google how to install pandas and jupyter notebook, I’m not your mother.